It's Time to Break-Up With Multiple Pass Estimation for Classification

TL;DR
Multiple pass estimation used for classification pairs the estimation and classification processes into one step, but it messes up the quality of the metal values calculated for each block. It’s a commonly used approach that some justify by thinking it helps estimation, which is flawed thinking for various geological and geostatistical reasons. But you can still use a multiple pass methodology for classification by running the classification process separate from estimation that uses a set of search parameters purpose-built for classification. Then estimation can be completed separately using its own set of search parameters optimized for calculating metal values!
Multiple Pass Estimation for Classification
You can use many methods to classify a resource as measured, indicated, and inferred. Multiple pass estimation pairs estimating metal values, using kriging or inverse distance, with classification. Typically, this would consist of a sequence of estimation runs that flag each block with the run number that they first meet a set of search restrictions and has a metal value estimated. Search restrictions used for this approach consider some combination of various search ellipsoid sizes and the minimum number of composites and drillholes found within each ellipsoid. The runs are executed in sequence from run 1 to run 3. With each subsequent pass, multiple pass estimation reduces the restriction on the search parameters used, representing a decrease in confidence from the previous run. Classification is then determined by relating the estimation run number that each block was estimated in and classifies the blocks as measured (run 1), indicated (run 2), or inferred (run 3). Keep in mind that a metal value is only estimated once for each block when a block first meets a run’s search restrictions.
It Doesn’t Make Sense!
It isn’t groundbreaking to say that the parameters you use for estimation influence the estimated metal values quality. And if you base the selection of those parameters on anything but geological and geostatistical considerations, the estimates calculated are not going to be optimal. In the case of multiple pass estimation used for classification, you’re picking arbitrary search ellipsoids and controlling the number of data used during the estimation process. While this approach will kill two birds with one stone, it doesn’t allow estimation algorithms to do their job properly, that job being to provide the best estimation possible given all relevant data. It also introduces artifacts in your block model at the boundary between runs that are purely derived from the sampling pattern instead of being constrained by (arguably) more relevant geological interpretations. I wonder how that abrupt change in your estimated metal values will affect pit optimization… Not well, I suspect. For these reasons, using multiple pass estimation for classification has never made sense to me. So, in the words of Michael Jordan:

Why is it so commonly used!?
This approach for classification is rampant within the resource reporting world. Enough so that it charges me up enough to go on a rant about it! Anecdotally, the vast majority of the 43-101 reports I’ve reviewed have used multiple pass estimation for classification. But if you don’t trust my account of its popularity, Silva and Boisvert (2013) surveyed 281 NI 43-101 technical reports published in 2012 to determine the prevalence of methods used to perform resource classification. The authors only used 120 of the reports in their study and did not consider the remaining 161 reports because of one of the following reasons:
- it didn’t have any classification (huh?);
- the report resources only reported inferred resources;
- it was a report for a deposit already considered in one of the 120 reports; or
- the report didn’t document the classification methodology used adequately to know what was done (okaaaayyyy… 🙈).
Of the 120 reports, 50% used a multiple pass search approach for classification. Unfortunately, the authors didn’t specifically tabulate the number of cases where classification was completed in combination with estimation or completed as a separate process. However, they did note that most of those 60 reports did combine the two, using multiple pass estimation for classification.
I’m not sure why this classification method is so popular, as it takes a simple thought experiment to guide practitioners away from it. I guess that it’s just something that people have just always done, creating a precedent and justification for people to keep using it? Is that valid rationale, though, given all the issues with the approach? I don’t think so…
Alternative Methods for Classification
Classification is a hard balance between being as technically precise and accurate as possible and communicating the method to the public and other interested parties clearly and concisely. Suppose you get too cute and do some crazy complicated classification method that considers your data’s underlying spatial structure, the deposits anisotropy, irregular spaced data, and your geological understanding, creating the most robust classification scheme. In that case, it’s going to be very hard for others to understand it truly. But if you get too simple, you can do something like create tubes of indicated or measured that follow drillhole traces that look ridiculous and communicate you don’t understand the deposit or how to control the method you are using for classification.
Multiple Pass Classification
The name of the method I’m about to explain will be a bit confusing at first, but stick with me! The easiest classification method for people to switch to if they use multiple pass estimation is what I call “multiple pass classification.” The keyword that is different here is “classification,” not “estimation.” The distinction between the two schemes is that multiple pass estimation combines the metal estimation process with classification, while multiple pass classification separates the two. Here is how you’d go about using multiple pass classification.
First, determine the set of search parameters optimized for estimating the best possible metal value with krigin (or inverse distance… I guess 😓), given the problem at hand. In the case of a resource estimate used to report the contained metal of a deposit, those parameters would probably include a single search ellipsoid while restricting the maximum number of data and the maximum number of data drillhole. This parameter configuration will help deal with smoothing issues, so your grade tonnage curves will be right once a lower-cutoff is considered. For more info on how to determine those parameters, check out this post by Clayton and Jared here, particularly what they call an “interim estimate.”
Second, establish what the combination of search parameters will be for each classification run that will be used to assign the different confidence levels of measured, indicated, and inferred. This set of parameters would be similar to what you’d use if you were doing estimation simultaneously. However, now you have far more flexibility in the parameters you can use, as you’re not worried about the quality of the metal values estimated by kriging!
So by separating the two processes, the best of both worlds! You can see the brutal artifacts produced by multiple pass estimation in the image below and how you can apply the same classification ontop of estimation completed using optimal parameters! Way better!
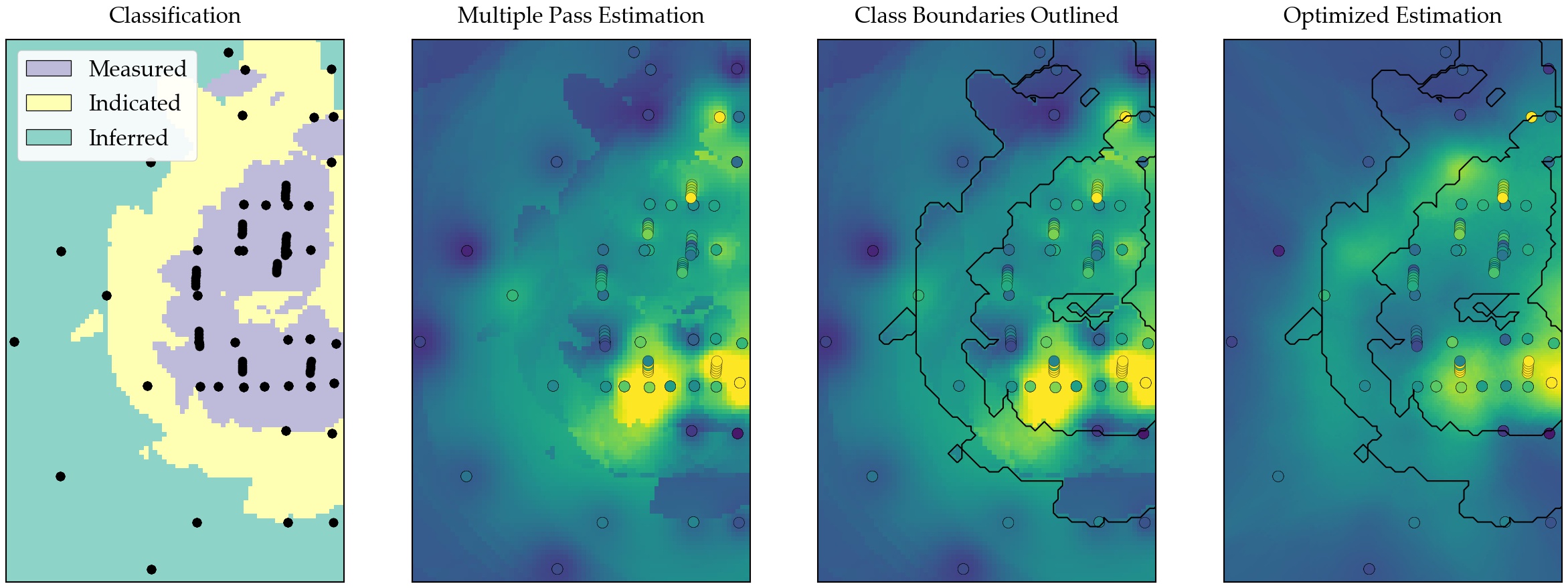
Conclusion
There are many ways to classify and resource block models, some better than others. Going through alternatives such as data spacing paired with uncertainty models would have ballooned this post, so look for us to cover some simple and more complex options in the future. Ultimately, it’s up to the resource geologist or engineer’s discretion to determine what is reasonable and defendable. If it were easy to define a “golden rule” for classification, I would have rambled on about some other topic! Instead, we have to do the best we can given the available data, understanding, techniques, and, most regrettably, the amount of time available to us.
Additional Readings and Resources
- Deutsch, C. V., & Deutsch, J. L. (2015). Introduction to Choosing a Kriging Plan. In J. L. Deutsch (Ed.), Geostatistics Lessons. Retrieved from http://www.geostatisticslessons.com/lessons/introkrigingplan
- Rossi, M. E., & Deutsch, C. V. (2014). Mineral Resource Estimation. Edmonton AB: Springer Netherlands. https://doi.org/10.1007/978-1-4020-5717-5
- Silva, D. S. F., & Boisvert, J. B. (2013). Mineral Resource Classification (NI 43 ‐ 101): An Overview and a New Evaluation Technique (Vol. 2013). http://www.ccgalberta.com